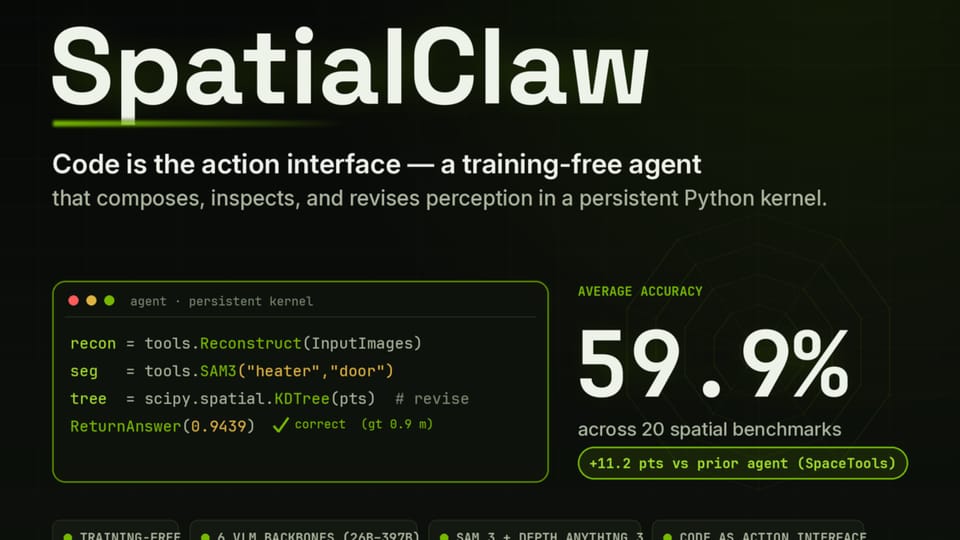
NVIDIA Research has introduced SpatialClaw, a training-free framework designed to address the persistent challenges vision-language models (VLMs) face regarding spatial reasoning. While modern models often struggle to accurately identify object locations, relationships, and 3D movement, SpatialClaw overcomes these limitations by utilizing code as the primary action interface for an agent loop. By allowing models to interact with perception tools through a stateful Python kernel, the system achieves a 59.9% average accuracy across 20 benchmarks, outperforming the previous state-of-the-art agent, SpaceTools, by 11.2 points.
Rethinking the Action Interface
The research team identified that the bottleneck in spatial reasoning often lies in how an agent communicates with its perception tools. Traditional methods, such as single-pass code generation or structured JSON-based tool calls, often force models to commit to a strategy before observing intermediate results or prevent them from performing necessary test-time computations. SpatialClaw changes this by wrapping an agent loop around a persistent Python kernel. This allows the model to compose tools, inspect outputs like masks and depth maps, and revise its approach dynamically.
This iterative process is structured into a five-stage loop: planning, code generation, execution, feedback assembly, and final answer submission. Because the system is training-free, it does not require fine-tuning or specific data for different backbones. It consistently applies the same system prompt and toolset across various models, ranging from 26B to 397B parameters, including the Qwen3.5/3.6 and Gemma4 families.
Performance and Geometric Reasoning
SpatialClaw demonstrates significant improvements in tasks that require chaining geometric computations across multiple frames and viewpoints. Controlled experiments isolating the action interface revealed that code composition accounts for over 52% of the performance gains over structured tool-call methods. The framework saw its most substantial improvements in dynamic tasks, with DSI-Bench scores rising by 17.6 points and MindCube scores increasing by 15.3 points on the Gemma4-31B backbone.
The framework provides access to essential perception tools, including Depth Anything 3 for reconstructing 3D scenes and SAM 3 for video and image segmentation. These tools return outputs as standard Python variables, enabling the agent to utilize libraries like NumPy or SciPy for precise calculations, such as finding the closest distance between objects using a KD-tree.
Practical Applications
The design of SpatialClaw is particularly well-suited for embodied agents and robotics that require metric distance measurements and multi-view inspection. By enabling the recovery of an object's orientation from various camera angles and tracking motion across 4D video data, the framework provides a robust solution for indoor scene question answering. Because the system functions without the need for additional training, it offers a flexible way for developers to enhance the spatial capabilities of existing VLMs in real-world environments.
Comments (0)
to join the discussion
No comments yet
Be the first to share your thoughts!